The grand jury decided not to indict Officer Darren Wilson on murder charges was the first historic event I followed on twitter. I felt helpless, anxious, and inspired as I read the feeds. After a few hours it occurred to me that someone should be archiving this information, but I couldn’t be sure anyone was. How many people do “digital history/humanities” work anyway? So a few hours after the decision was announced I activated an archive on the online tool, Tweet Arivist, to collect all of the tweets on #Ferguson and #MikeBrown. I have now made that archive public on the site Figshare. What follows are some suggestions for how scholars might interact with this twitter data.
I have some experience working with tweets as sources. After the death of Nelson Mandela I developed a qualitative method to analyze how people were speaking and remembering Madiba on twitter. You can find a detailed description of this method and look at the short products they inspired here. My approach was simply to cull through all of the material, identify trends and tag the tweets. Then I searched my tags to see how people were talking about Mandela after his death.
I used Tweet Archivists to collect my tweets. The site requires a subscription, but I think that in cases where collection is time sensitive it is worth the money. The site exports these tweets as pdf or xlsx files. It also has several built in analytic tools. I used the built in word cloud generator to identify jumping off points. I then performed in-text searches to find the tweets that mentioned those words and then crated a new column to tag these tweets. I used the program OpenRefine for this, because it allows users to search texts and batch edit. For information on using OpenRefine, see Thomas Padilla’s great resource: getting started with OpenRefine.
Once I uploaded my Madiba dataset to OpenRefine, I could search the tags and spend more time analyzing the data in those tweets. But that dataset is much smaller than the Ferguson dataset I collected. One approach to analyzing the Ferguson data might be to limit qualitative searches to specific time frames. Tweet Archivist packages the tweets it collects in bundles of about 500,000, and these are arranged chronologically in the data set. Researchers interested in analyzing reactions to specific news casts that might be biased or inflammatory might look only at the tweets posted immediately after the report aired. The researcher could then use OpenRefine to tag the relevant tweets.
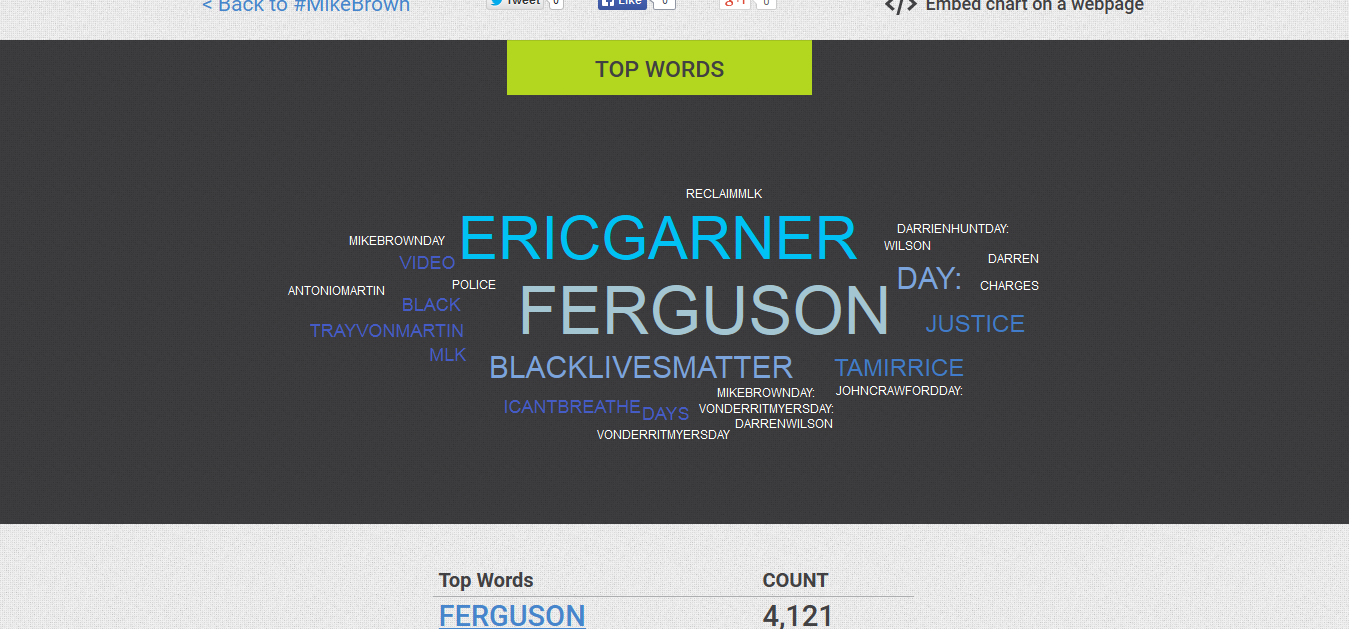
Since the data is hosted on Figshare those useful TweetArchivist tools won’t be available. Researchers interested in using this dataset will have to use their preferred program for creating word clouds. There are certainly many options out there, but I think AntConc is a particularly useful tool because it allows you to perform many different kinds of analysis. A big picture concordance analysis on this data set might yield some compelling information. A researcher could create plots that examine what words most often accompanied a word like “cop” or “fire” to closely examine how people talked about the protests that followed the Ferguson decision. Points that stand out can be examined again with a more qualitative lens. Micky Kaufman, uses AntConc’s concordance function to great effect in her Quantifying Kissinger project.
I encourage anyone interested to work with this dataset. It would also be helpful if scholars and institutions that have data on Ferguson linked to one another to raise the visibility of this data on the web. Tweet a link to @bradsh41, or leave a comment if you have a similar dataset you would like me to link to on my Figshare project.